|
Shrinivas Ramasubramanian I am an MS student in Robotics at the Robotics Institute, Carnegie Mellon University, working with Jeff Schneider on making model-based reinforcement learning more stable and sample-efficient under distribution shift. Previously, I was a research engineer at Fujitsu Research in Bangalore and a project assistant in the Vision & AI Lab (VAL) at IISc Bengaluru, where I worked with Yuhei Umeda, R. Venkatesh Babu, and Angela Yao on cost-sensitive learning, non-decomposable objectives, and temporal action segmentation. My work on objective-aligned semi-supervised learning and selective mixup fine-tuning has appeared at NeurIPS 2022 and ICLR 2024 (Spotlight), and I have recent papers on long-tailed temporal action segmentation at ECCV 2024 and BMVC 2024, as well as work on flatter-minima training for world models accepted to NeurIPS 2025. I completed my undergraduate degree in Electrical Engineering at IIT Bombay. |

|
ResearchMy primary area of focus is fairness, constrained optimization problems in deep neural networks. My secondary areas of research are classification on class-imbalanced data, semi-supervised and representation learning. Currently I am hoping to venture out into a couple of areas like large language models, video generation and data centric machine learning for unsupervised and semi-supervised learning. |
|
Improving Model-Based Reinforcement Learning by Converging to Flatter Minima
Shrinivas Ramasubramanian, Ben Freed, Alexandre Capone, Jeff Schneider NeurIPS, 2025 Model-based reinforcement learning pipelines often collapse once the policy leaves the world model’s nominal operating region. We introduce a flat-minima regularizer that pairs sharpness-aware updates with spectral control on the dynamics model, yielding stable rollouts and markedly higher sample efficiency under distribution shift across offline and online benchmarks. |

|
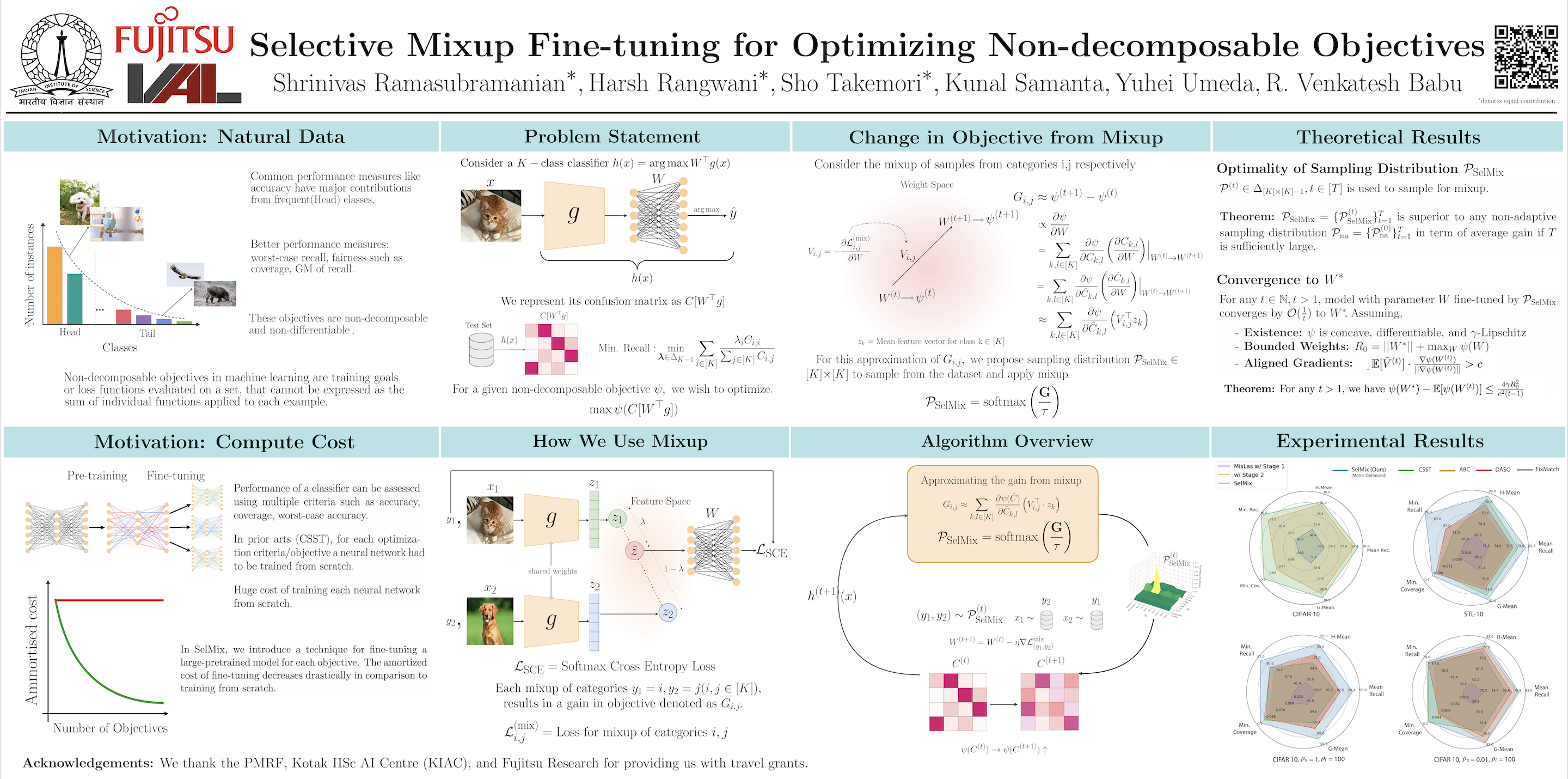
Selective Mixup Fine-Tuning for Optimizing Non-Decomposable Metrics
Shrinivas Ramasubramanian*, Harsh Rangwani*, Sho Takemori*, Kunal Samanta, Umeda Yuhei, Venkatesh Babu Radhakrishnan, ICLR, 2024 spotlight presentation, also presented at ICML workshop differentiable almost everything Internet usage growth generates massive data, prompting adoption of supervised/semi-supervised machine learning. Pre-deployment model evaluation, considering worst-case recall and fairness, is crucial. Current techniques lack on non-decomposable objectives; theoretical methods demand building new models for each. Introducing SelMix—a selective mixup-based, cost-effective fine-tuning for pre-trained models. SelMix optimizes specific objectives through feature mixup between class samples. Outperforming existing methods on imbalanced classification benchmarks, SelMix significantly enhances practical, non-decomposable objectives. |

|
Cost-Sensitive Self-Training for Optimizing Non-Decomposable Metrics
Harsh Rangwani*, Shrinivas Ramasubramanian*, Sho Takemori*, Kato Takashi, Umeda Yuhei, Venkatesh Babu Radhakrishnan, NeurIPS, 2022 This work introduces the Cost-Sensitive Self-Training (CSST) framework, which extends self-training-based methods to optimize non-decomposable metrics in practical machine learning systems. The CSST framework proves effective in improving non-decomposable metric optimization using unlabeled data, leading to better results in various vision and NLP tasks compared to state-of-the-art methods. |
|
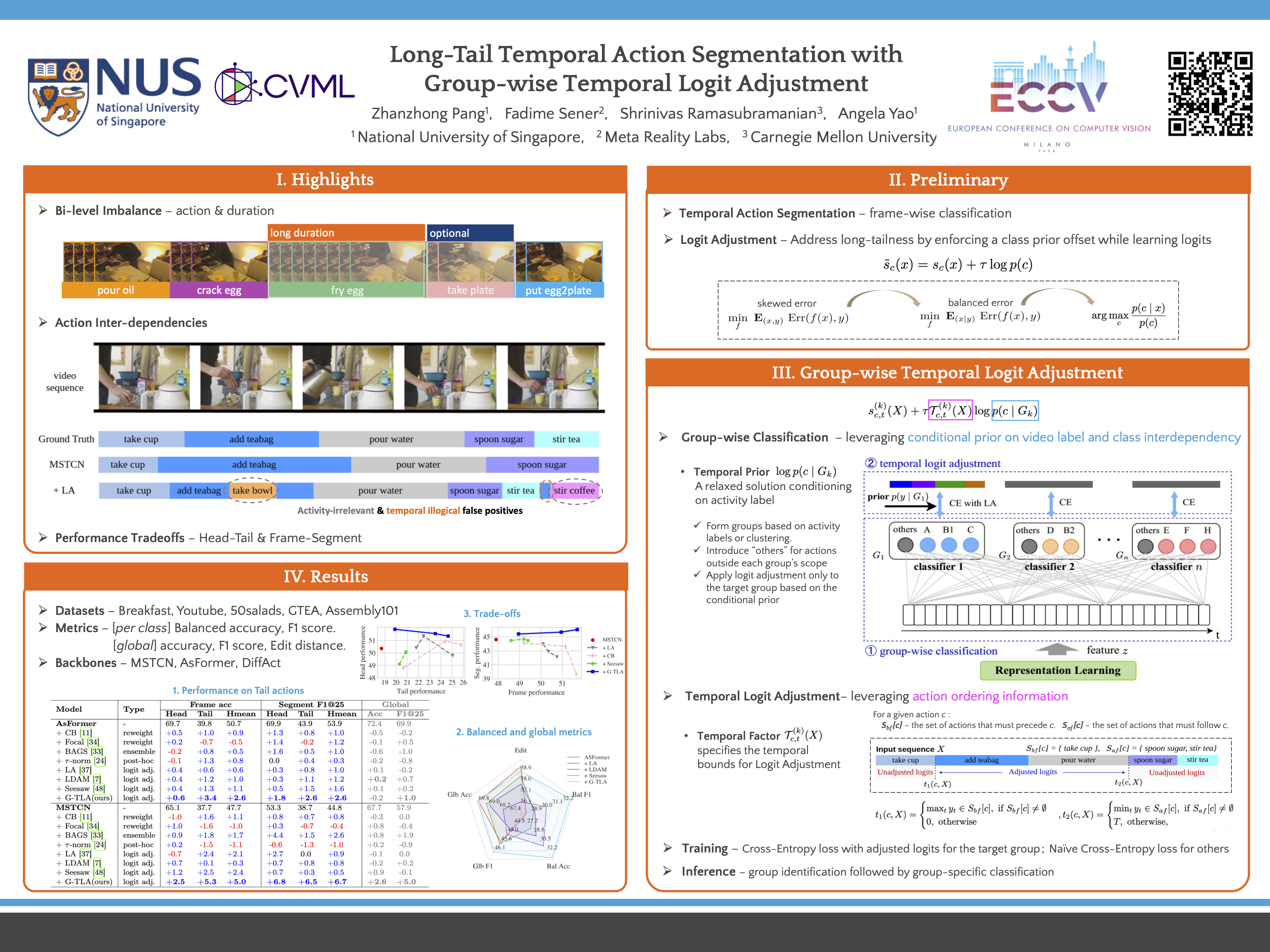
Long-Tail Temporal Action Segmentation with Group-wise Temporal Logit Adjustment
Pang Zhanzong, Fadime Sener, Shrinivas Ramasubramanian, Angela Yao ECCV, 2024 Temporal action segmentation assigns labels to each frame in untrimmed videos, often facing a long-tailed action distribution due to varying action frequencies and durations. However, current methods overlook this issue and struggle with recognizing rare actions. Existing long-tail methods, which make class-independent assumptions, also fall short in this context. To address these challenges, we propose a novel framework called Group-wise Temporal Logit Adjustment (G-TLA). G-TLA leverages activity information and action order to improve tail action recognition. Our approach shows significant improvements on five temporal segmentation benchmarks. |

|
Cost-sensitive learning for long-tailed temporal action segmentation
Pang Zhanzong, Fadime Sener, Shrinivas Ramasubramanian, Angela Yao BMVC, 2024 Temporal action segmentation in untrimmed procedural videos aims to densely label frames into action classes. These videos inherently exhibit long-tailed distributions, where actions vary widely in frequency and duration. In temporal action segmentation approaches, we identified a bi-level learning bias. This bias encompasses (1) a class-level bias, stemming from class imbalance favoring head classes, and (2) a transition-level bias arising from variations in transitions, prioritizing commonly observed transitions. As a remedy, we introduce a constrained optimization problem to alleviate both biases. We define learning states for action classes and their associated transitions and integrate them into the optimization process. We propose a novel cost-sensitive loss function formulated as a weighted cross-entropy loss, with weights adaptively adjusted based on the learning state of actions and their transitions. Experiments on three challenging temporal segmentation benchmarks and various frameworks demonstrate the effectiveness of our approach, resulting in significant improvements in both per-class frame-wise and segment-wise performance. |

|
Semantic Graph Consistency: Going Beyond Patches for Regularizing Self-Supervised Vision Transformers
Chaitanya Devegupta, Sumukh Aithal, Shrinivas Ramasubramanian, Yamada Moyuru, Manohar Koul, CVPR, 2024 Self-supervised learning (SSL) with vision transformers (ViTs) excels in representation learning but often underutilizes ViT patch tokens. We introduce the Semantic Graph Consistency (SGC) module, which enhances ViT-based SSL by treating images as graphs, with patches as nodes. This approach uses Graph Neural Networks for message passing and regularizes SSL by enforcing consistency between graph features across different image views. |
Patents
|

|
Information processing apparatus and machine learning method
Harsh Rangwani, Shrinivas Ramasubramanian, Sho Takemori, Kato Takashi, Yuhei Umeda, R. Venkatesh Babu US Patent · US20230376846A1 Covers systems that adapt machine learning objectives within information processing devices for cost-sensitive and fairness-aware optimization. |
|
|
Machine learning method and information processing apparatus
Shrinivas Ramasubramanian, Harsh Rangwani, Kunal Samantha, Sho Takemori, Yuhei Umeda, R. Venkatesh Babu US Patent Application · US20250037023A1 Describes a learning routine that adapts supervision signals and deployment constraints for robust model updates within practical information-processing pipelines. |
Academic Service
1. Served as reviewer for NeruIPS'23, AAAI'24, ICML'23 and ICLR'24 |
Notable projects
|

|
See in the dark: Adversarial training for image exposure correction
Shrinivas Ramasubramanian*, Srivatsan Sridhar*, Course project EE:710, IIT Bombay, 2018 The project aims at achieving an image transformation from a low exposure image taken in a dimly lit environment to that taken by a long exposure camera. The dataset used is the SID dataset prepared thanks to C. Chen et al. For detailed analysis, please refer to the project report named report.pdf. |

|
Semantic Segmentation for autonomous vehicles
Shrinivas Ramasubramanian*, Project under SeDriCa: Autonomous Vehicle Development, IIT Bombay, 2019 This work involves the use of an encoder-decoder architecture CNN for semantic segmentation of the image. We took inspiration from LinkNet and trained our model on both the Mapillary dataset and the Berkeley Deep Drive dataset. |
|
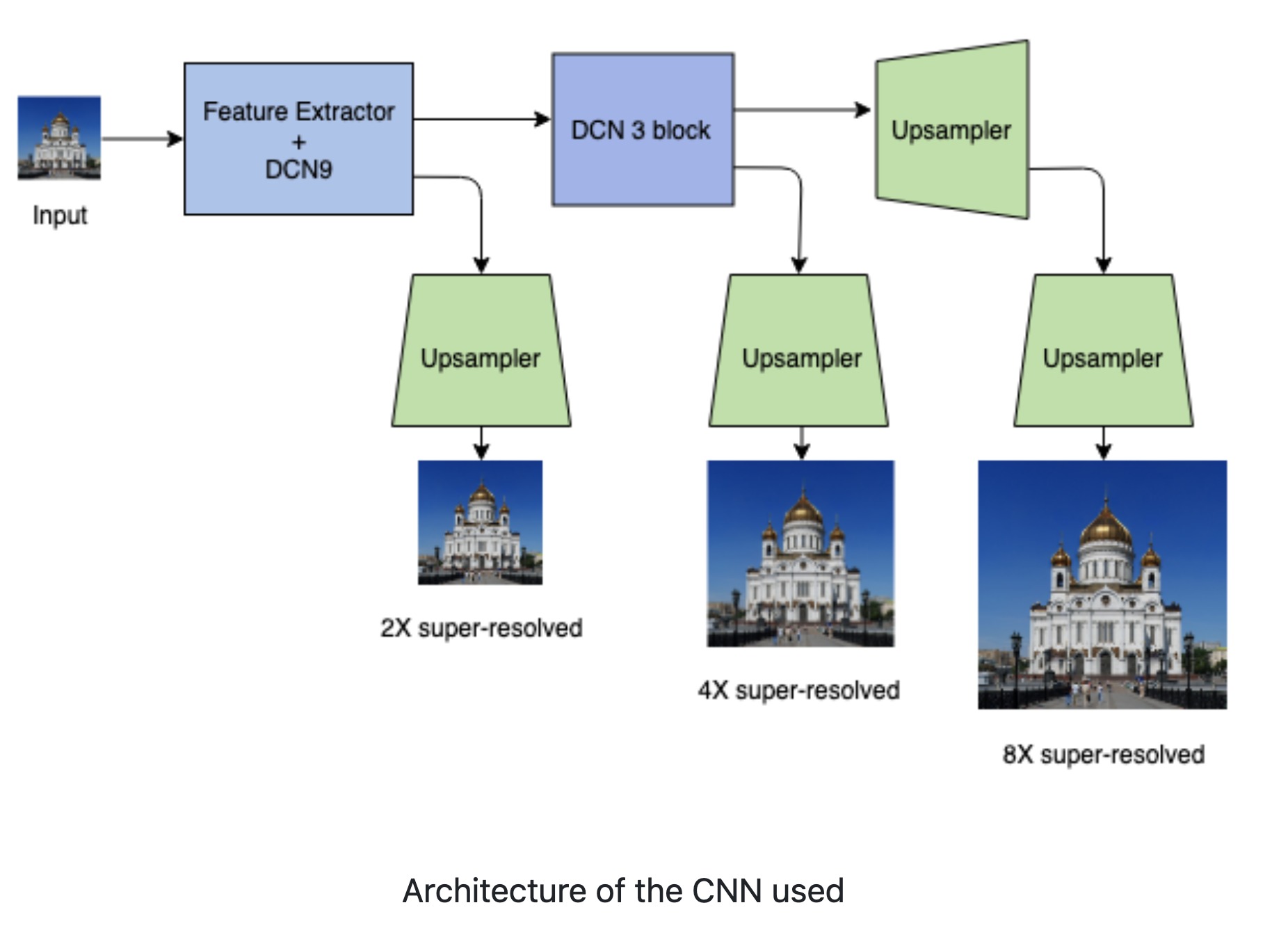
Image Super Resolution
Shrinivas Ramasubramanian, Course project, IIT Bombay, 2018 This project incorporates a supervised super-resolution scheme by having the process of super-resolving the image to a slightly lesser resolution. This approach allows the model to learn necessary features at each scale of resolution. This work is highly inspired by Yifan Wang et al., who followed a similar progressive super-resolution approach. |
|
Feel free to steal this website's source code. Do not scrape the HTML from this page itself, as it includes analytics tags that you do not want on your own website — use the github code instead. Also, consider using Leonid Keselman's Jekyll fork of this page. |